
DecaNLP
The Natural Language Decathlon is a multitask challenge that spans 10 tasks. In their model, they treat everything as question answering, which seems very nice to me.
The following table shows the tasks included in DecaNLP:
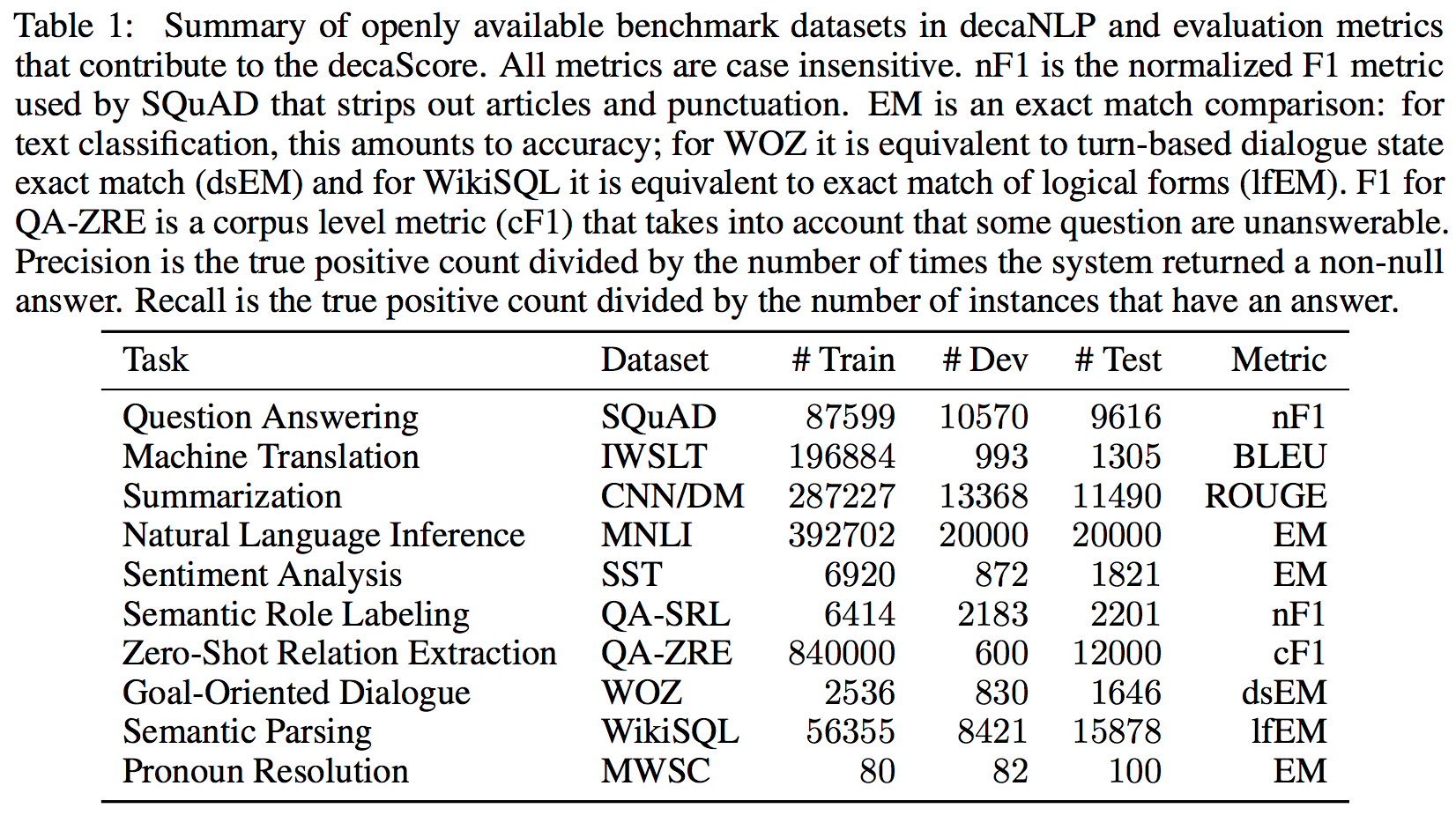
The following image shows how different tasks are formatted into QA in DecaNLP datasets:

GLUE
GLUE collects 9 tasks built on existing public datasets. They are single sentence or sentence pair classification tasks. GLUE also provides evaluation platform, baseline models, expert-constructed diagnostic set, private testing sets, and single-number target metric.
The following table shows the tasks included in GLUE:
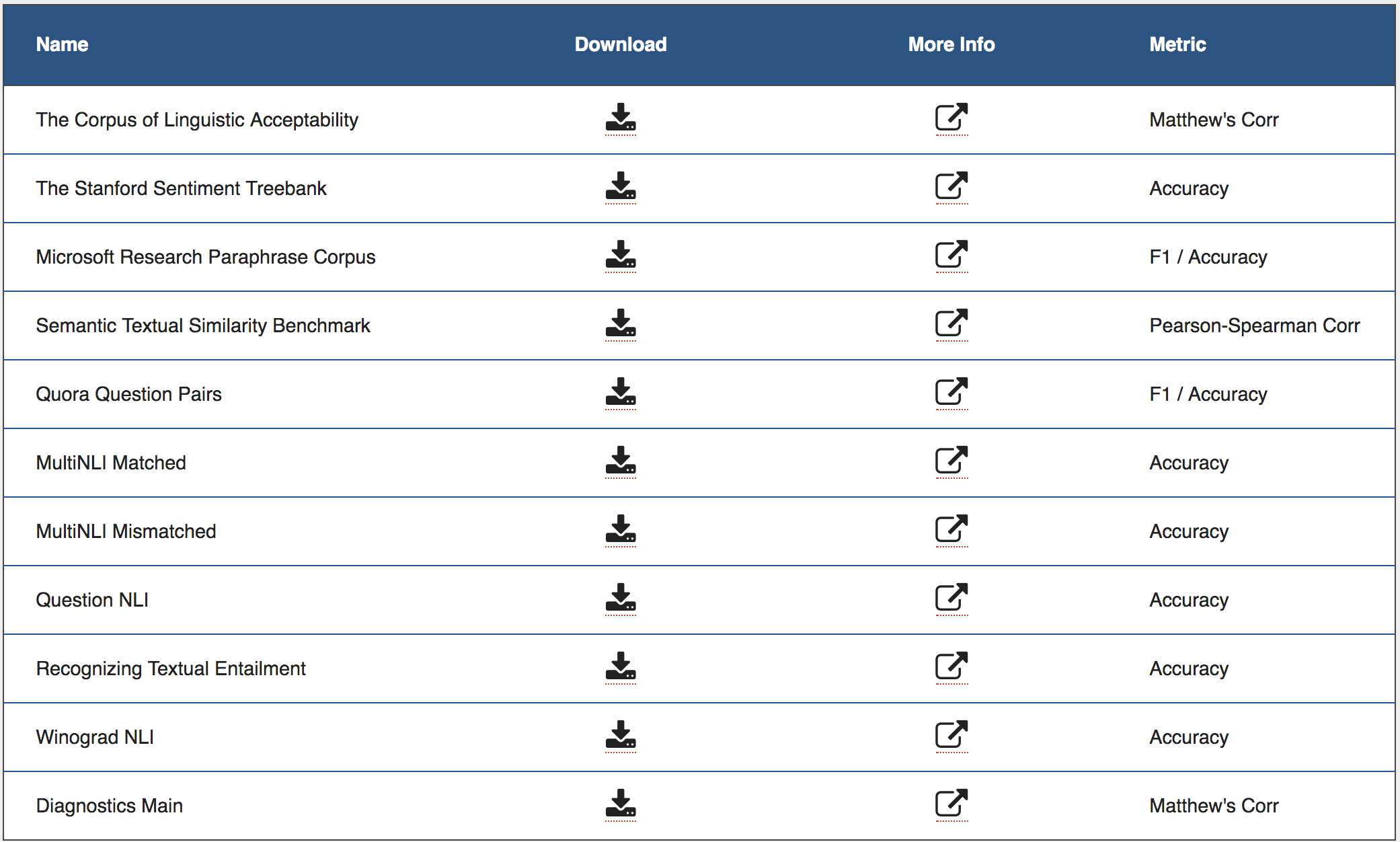
Compared with DecaNLP, BLUE provides error analysis toolkit, and it is pursuing a more immediately practical goal.
SuperGLUE
As existing models on GLUE reach similar performance with human in terms of evaluation metrics, the head room on the GLUE benchmark has shrunk dramatically. SuperGLUE (from the same group authors of GLUE) provides harder language understanding tasks compared with GLUE.
- SuperGLUE provides 7 tasks which are significantly harder than those in GLUE.
- Human performance estimates are included.
- Tasks formats has expanded, not just text or text-pair classification.
- Platform, toolkits are provided.
- Better governing of leaderboard for fair comparison.
The following table shows the tasks included in SuperGLUE:
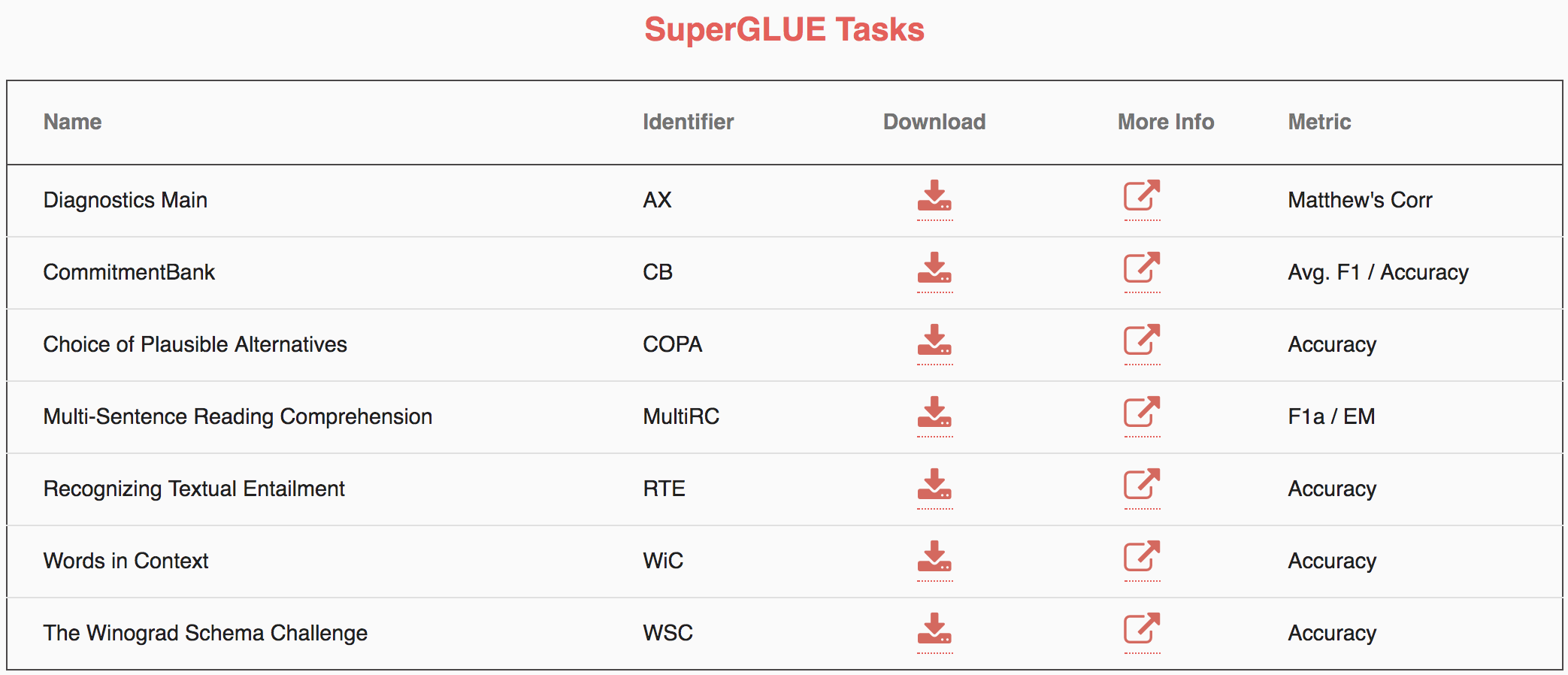
Comments
To build a benchmark, we need to select tasks which requires core abilities for language understanding. We also need to make the datasets cover different aspects of understanding. The datasets can be from existing datasets. The data format can be processed, and event unified.
Except from datasets, we can also provide leadboard, website, toolkits, human performance, diagnostic sets, private test sets, evaluation metric and so on.
Aside from general language understanding, we can construct leadboard for other language such as Chinese. Besides, constructing benchmarks for domain-specific applications is also valuable.
References
DecaNLP website: https://decanlp.com/
DecaNLP paper: https://arxiv.org/pdf/1806.08730.pdf
GLUE website: https://gluebenchmark.com/
GLUE paper: https://openreview.net/pdf?id=rJ4km2R5t7
SuperGLUE website: https://super.gluebenchmark.com/
SuperGLUE paper: https://arxiv.org/pdf/1905.00537.pdf